We built this working through a legal handover.
That sounds mundane, but it is exactly the kind of problem where AI starts to feel useful. Not because the model knows anything magical about our company, but because the work is full of scattered context: old files, previous decisions, email threads, notes, folders, drafts, and half-remembered explanations that never made it into one clean place.
The job was not simply to read legal documents. The job was to rebuild the operating context around them.
Our Legal Cleanup
Legal handovers are context problems first.
Before anyone can give useful advice, they need to understand what exists, what matters, what has changed, and where the important details live. That usually means a lot of manual work: collecting documents, checking folders, summarising old material, spotting gaps, and turning messy history into something another person can inspect.
We used AI to help with that cleanup. Codex and Claude Code were useful because they could work directly with files and folders, not just answer questions in a chat window. They helped pull material together, summarise it, reorganise it, and make the shape of the work easier to see.
The first version worked, but it had a problem: the output was mostly markdown.
Markdown is good for models. It is simple, lightweight, and easy to generate. But once the context gets dense, it becomes a poor human surface. You can scroll through it, but you do not really browse it. Tables, links, sections, notes, document groups, and status indicators all feel slightly compressed into text.
That matters because humans still need to inspect the work.
A Surface For Both Humans And Machines
Thariq Shihipar had a line that clicked for us: “HTML is the new markdown.”
That became the next experiment.
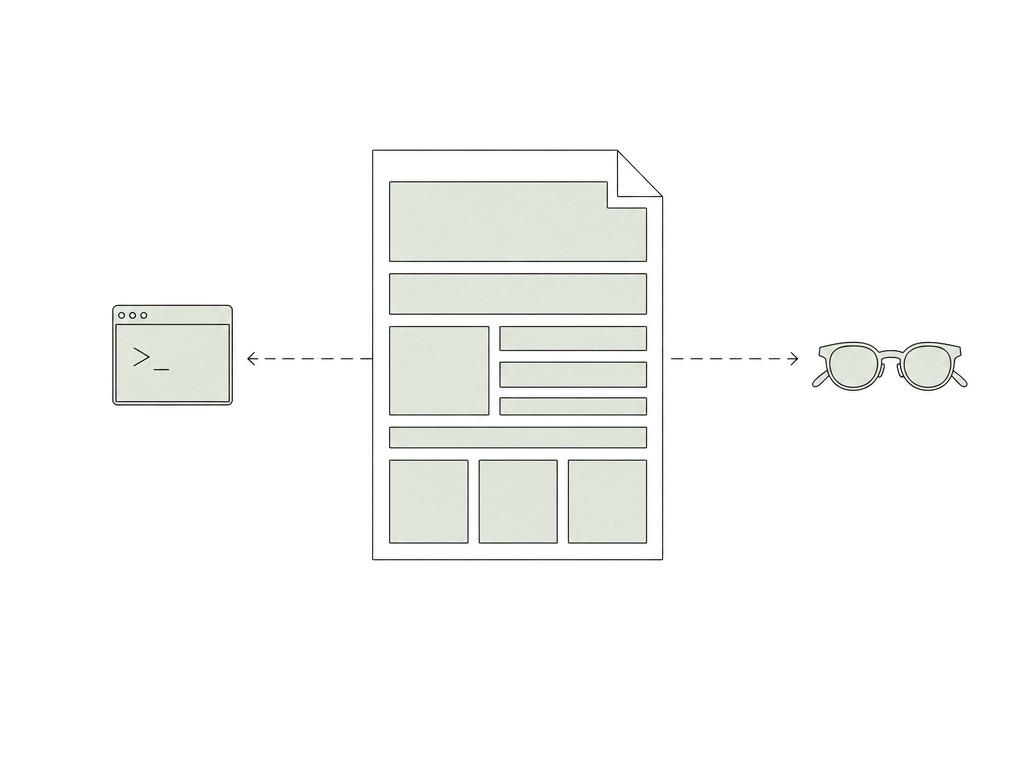
We asked the models to turn the legal cleanup into simple HTML. Not a web app. Not a heavy dashboard. Just clean, minimal HTML files that matched the way we wanted to read the material.
The difference was immediate.
HTML gave us hierarchy, tables, links, sections, summaries, and visual rhythm. It let us move from “a pile of generated notes” to something closer to a working surface. We could scan it. We could jump around it. We could send it around internally. We could imagine sharing parts of it with counsel.
The important point is that HTML did not make the context worse for models. If anything, it made the structure clearer. Minimal semantic HTML is easy for LLMs to parse. Headings, tables, anchors, lists, and sections all carry useful meaning.
Markdown is a good format for passing text around. HTML is a better surface for working with context.
Making Context Editable
The next step was making the surface editable without making it chaotic.
We built a small inline editing harness. The idea was simple: highlight a section, ask for a change, and let the model apply that change through a constrained set of roughly ten atomic operations.
That constraint mattered.
We did not want the model freely rewriting the whole file every time we asked for a small correction. We wanted changes that were narrow, reviewable, and diffable. Insert this. Replace that. Move this section. Update this table. Add a note. Remove a stale item.
The goal was not to make the model more powerful. It was to make the model’s changes easier to trust.
A Shared Context For All Our LLMs
This is where the experiment started to feel bigger than the legal handover.
At Kerva, we use different models for different jobs. Codex and Claude Code are useful for building software. Grok is useful for current research. Gemini is useful for visual and multimodal work.
Each tool has strengths. The annoying part is context.
Every time we move between tools, we have to rebuild the state of the conversation. One model knows what we meant. Another starts cold. Chat history becomes fragmented. The human becomes the context router between AI products.
That feels wrong.
What we wanted was a context layer we owned: clean folders, durable HTML files, and a shared surface that humans could browse and models could read or update. Not context trapped inside one chat product. Not a messy archive of prompts. A working repository of company context.
Maybe A Product
This started as a build note, not a product announcement.
But the best product ideas often start as your own problem becoming too annoying to ignore.
Legal handover is one version of the problem. Finance, fundraising, hiring, operations, diligence, product planning, and personal admin all have the same shape. Context gets scattered. Humans need to inspect it. Models need to work with it. Different AI tools need access to the same source of truth.
Maybe the answer is not another chatbot.
Maybe it is a shared context layer: owned by the team, readable by humans, parseable by models, and editable through controlled operations.
That is what we are working on. Not because we are sure it is a product yet, but because it solved a real problem for us.